亚马逊一路发展下来,竞争愈加强烈,所需要的资源匹配精力匹配都在呈倍增加,每个平台红利结束后,对应运营理念也需要及时更新升级。
本文价值:电商数据化
亚马逊一路发展下来,竞争愈加强烈,所需要的资源匹配精力匹配都在呈倍增加,每个平台红利结束后,对应运营理念也需要及时更新升级。
本文价值:电商数据化
在电商业务中或大部分与人和市场有交集的岗位中都会需要用到跨学科综合性的技能知识,分析调研、市场营销、财务管理、统计、项目管理、组织行为学等等。
本文价值:BCG Matrix
如果说互联网时代必须要掌握的一项技能是什么?我觉得是主动获取信息的能力。
生活中工作中我们遇到的问题80%的问题是别人解决过了的,我们通过search就可以获取、参考、使用,剩下的20%需要我们进行多次的深入research,也就是整合研究。
本文价值:快捷google
电商平台的核心引擎大致分为两块,搜索架构和产品布局,应该说各有各的特色。当然今天的主题是反爬虫机制,电商平台如何能保护好自己的数据,又不影响正常用户体验,所谓当今业界一场持久的攻防博弈。
应用场景一:静态结果页,无频率限制,无黑名单。
攻:直接采用scrapy爬取
防:nginx层写lua脚本,将爬虫IP加入黑名单,屏蔽一段时间(不提示时间)
应用场景二:静态结果页,无频率限制,有黑名单
攻:使用代理(http proxy、VPN),随机user-agent
防:加大频率周期,每小时或每天超过一定次数屏蔽IP一段时间(不提示时间)
应用场景三:静态结果页,有频率限制,有黑名单
攻:使用代理,随机1-3秒爬取,爬10秒休息10秒,甚至范围时间爬取,增加机器
防:当5分钟内请求超过60次,弹出验证码页面,通过验证增加5分钟无限制时间,不通过验证码则屏蔽增加一小时 (时间自拟)
应用场景四(Amazon):静态结果页,有频率限制,有黑名单,有验证码
攻:python+tesseract验证码识别库模拟训练,或基于tor、crawlera(收费)的中间件(广度遍历IP)
防:前端异步加载js,动态加密token
应用场景五(Aliexpress):动态结果页,有频率限制,有黑名单,有验证码
攻:python+Selenium,利用chrome内核加载动态结果页,更推荐用node+hex+ie内核做一个爬取客户端。java程序可以参考《简单破解Java浏览器组件jxbrowser》
防:见二阶爬虫
一阶爬虫属于单纯的技术性博弈,下面开始真正的人机交互博弈
应用场景六(PC天猫搜索页):https,动态结果页,有频率限制,无黑名单,有验证码
防:基于个性化为主导,提倡用户主动登陆来获取更优质的用户体验。根据购买习惯为用户推荐一些正常促销的商品,如9.9洗发露、沐浴露、茶叶等(威露士经常做),以及一些优质的钻展商品。不但能区别人机,还能搜集用户访问喜好,针对性优化个性化大数据,还可以抵御ddos,可谓一举三得
攻:搜集刷单账号,用分布式任务
应用场景七(生意参谋):https,React单页面应用,有验证码,LocalStorage,机器学习中间件
防:生意参谋本身是收费类的官方服务,从内测http过渡到https,而且近期加大对采集行为的打击,直接采取封号警告策略。以增加用户采集成本为限制,约束攻击方收敛性为。
单页面应用访问是遵循一定正常轨迹的。例如请求:
用户信息获取
数据列表1
数据列表2
数据详情1
…
针对数据可视化应用,大部分数据是经计算分析得到,并不会经常改变(甚至不变)。那么,数据结果存储入LocalStroage中,不但节省了网络请求加快页面速度(相当于缓存),还能区分用户行为轨迹。
详细的来说,通过程序编程得到的爬虫,无论是基于url request,还是基于解压webkit(如:jxbrower)。所生成的爬虫对象都是临时对象,那么不会存储LocalStroage数据,因此导致,访问数据页的请求轨迹每次都会是
用户信息获取
数据列表1(实际应被存储到LocalStroage)
数据列表2(实际应被存储到LocalStroage)
数据详情1
…
而正常用户行为(一直通过浏览器访问重复页面)
用户信息获取
数据详情1
… 总之,不会请求LocalStorage里有的
![生意参谋] (http://image.3001.net/images/20170619/14978650932159.png)
加解密的JS代码
1 | setItem: function(e, t) { |
另外,单页面应用是异步加载数据,一个页面中有ABC三类,只有A类需要验证码时用dialog占屏,BC类数据正常显示,爬虫开发时必然考虑不到这些情况,验证码并非强制要求输入(刷新后照常访问)
还可以分析每天用户请求数,访问习惯等等
分析用户行为轨迹的方式大致有3种:nginx流量中间件,web controller层拦截器,日志收集(flume + hadoop + sperk)* 。可能基于贝叶斯或决策树分析【实际怎么算只有开发者知道】
曾经被封过一次, 不是实时性的第二天才被封, 所以应该时 日志离线计算 得出的结果
攻:chrome插件(可获取https流量),另外把页面中的跳转链接记录到数据库中.因为一些链接只需要修改日期或ID等参数就可以复用. 链接中的一些铆点可能就是计算用于轨迹的因素. PS:这也是生意参谋一直警告的方式, 所有行为由读者自行负责, 与本文作者无关。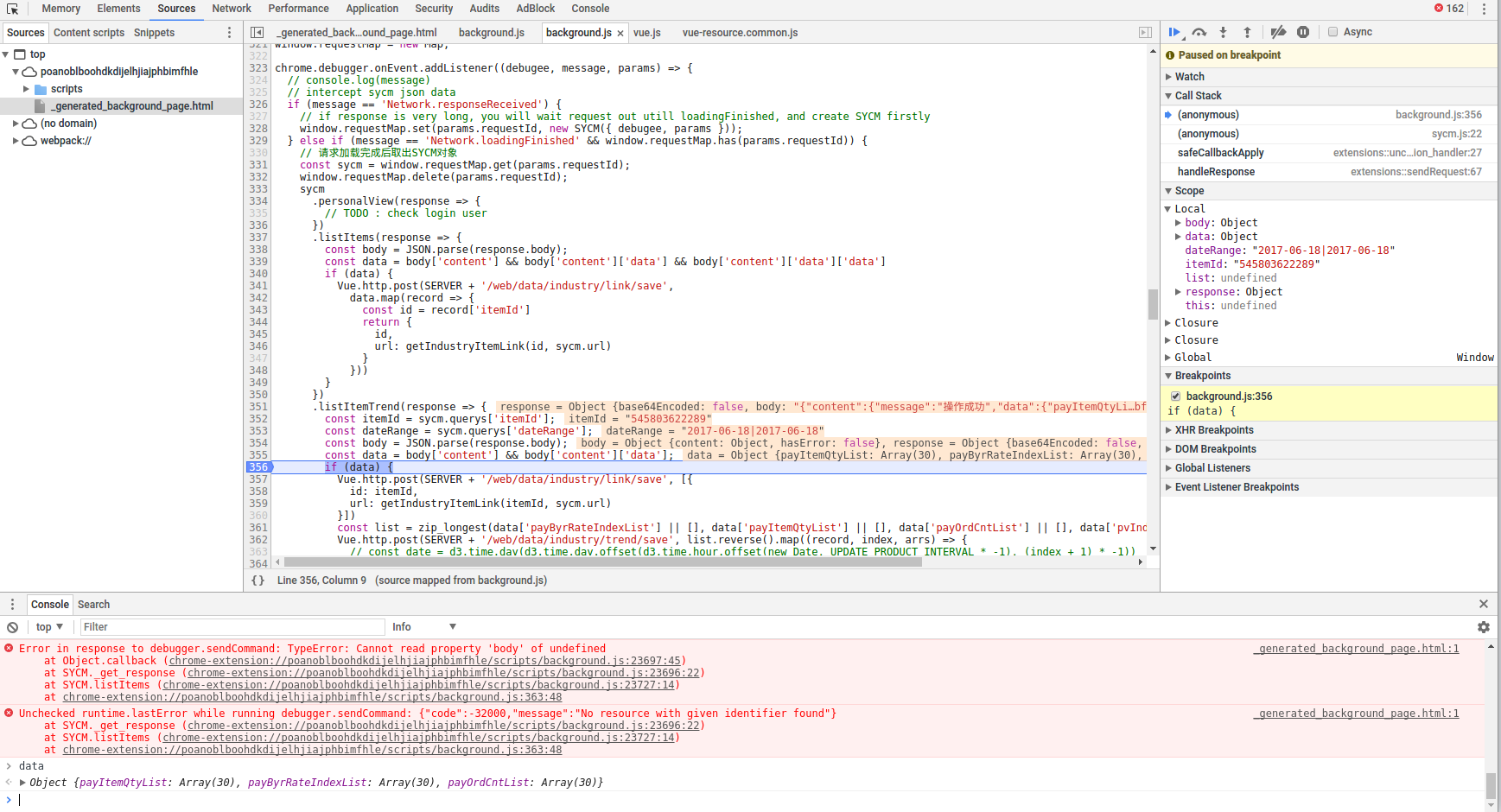
讲道理攻击方为何需要去爬取电商平台的数据,就为一个目的,逆演算出平台的权重计算,推导出各类合理范围内的指标(配合刷单,刷流量)。从技术层面上,永远是一个相互博弈的过程,如果有人下血本采用半人工,堆机器的方式暴力抓取,也是难以防控的。而且众所周知,电商技术的转化含金量非常高,机器和人工的成本就是九牛一毛,如果你的模型与业务模型擦边,辅助上一些内部渠道,无论是作为商家还是服务商都极快的变现
因此,反爬虫的最终核心点是要让攻击者不知道自己已经被判定为爬虫了。那么,攻击者只会悠哉的爬取数据,并兴高采烈的开始演算。而从平台方我们的最终目的是为了保护我们的数据和模型,那么关键点就来了。需要是让攻击方获取得数据不具有代表性,模型不可行即可。配合上流量木桶,定位到攻击者,我们将原始数据进行一些离散加工,加入一些噪音,让攻击方往错误的方向上推导模型。最终攻击方讲无法区分哪些数据是可用,那些又是噪音。
这时候,你会说,如果系统误杀正常用户,给出个一些展示数据错的离谱怎么办。这个度其实很好把握,我们只需要在排名*、成交单数、点击率等此类动态变化的维度加入噪音,不去加工价格、运费、产品详情,即使被程序判定为攻击者,并不影响正常用户的体验
*本文作者:leopard7777777,转载请注明FreeBuf.COM
从16年开始,始于Amazon,陆续结缘电商好几年。最开始是接触到淘宝,在大学时候,那时卖软件,一件铺货,无疾而终。后面从事外贸,又接触到跨境电商,从零到一做了很多工作,调研-注册-上新-学习视频-成交-思考。目睹了行业的飞速发展。这里总结一下从事电商的一些要点想法。
营销漏斗模型(Marketing Funnel)重点在于量化。
出于不同的目标,可以有各种不同要素的漏斗。
以目标反向倒推可以通过这个模型找到各要素需要做哪些工作,工作量几何。
以目前工作状态正向预测可以通过这个模型找到未来的目标达成率是否能达满足预期,缺口几何。
不管正向还是反向使用,重点是找到影响要素和接近准确的相邻环节的转化率。以目标为导向来指导后面工作的开展框架,并找到薄弱环节集中突破。但同时要注重过程控制,不断调整临时的变化。比如预期广告投放量在FB上转化比实际要低,就需要考虑调整一下投放在站内广告的比例或修改广告内容。量化–>行动–>过程控制–>达成目标转化率。
4P 和 4C
产品端:Product Price Place Promotion
客户端:Customer Cost Convenience Communication
4P以市场需求为导向,4C以客户需求为导向。两种思维方式要一起用,大方向用4P,小方向用4C。
Product产品:让产品赞美生活
Price价格:没有所谓的科学定价,定价本质是各环节想赚多少。重点是让消费者觉得物有所值。
Place渠道:利益链条每一链条的利益分配关系
Promotion促销:辅助作用,本质是无限放大产品与人的关系,强化购买理由。
Customer客户:满足直接需求和潜在需求
Cost成本:客户愿意付出的成本、代价是多少
Convenience便利:操作上的和时间上的
Communication沟通:被尊重被认同
市场营销的经典定义:有盈利的满足顾客需求。
现金流:
缩短回款周期,减少物流时间,有意识延长物流付款周期。
流动比率(Working Capital Ratio):强调流动,流动的资产/流动负债
保持一定的负债的规杠杆化
【大数据分析-上市跨境企业的流动比率情况】 待完成
波士顿矩阵(BCG Matrix):市场增长率-相对市场份额矩阵、波士顿咨询集团法、四象限分析法、产品系列结构管理法等。其认为公司若要取得成功,就必须拥有增长率和市场份额各不相同的产品组合。组合的构成取决于现金流量的平衡。
这种思维方式是选取两个重要的量化指标建立坐标系,对产品进行分类,从而合理安排分配精力、资源投入比例。典型分为:明星类、问题类、奶牛类、劣狗类。
象限是动态的,明星产品的目标是成为现金牛,问题产品需要摆脱泥沼增加市场分额,而所有产品都可能衰退为劣狗。重点是找到阶段产品所处的周期给到对应的理解和发展方向。
电商SKU使用
以曝光量和利润率为坐标系,将不同产品分布的区域找出来
| 商品 | 曝光量 | 利润率 | 类别 | 策略 |
|---|---|---|---|---|
| 商品A | 10000 | 3% | 带量产品 | 导流产品,维稳并提高关联销售 |
| 商品B | 5000 | 30% | 明星产品 | 现金流产品,注重售后优化体验 |
| 商品C | 500 | 15% | 潜力产品 | 增长曝光量、搜索权重 |
| 商品D | 500 | 3% | 鸡肋产品 | 优化转化率,实在不行的下架 |
同样的还可以用在其它参数组合如曝光量和转化率,利润率和回购率等等。重点是对繁多的产品进行归类和聚焦然后采取合适的策略。
时间管理
利用矩阵思维对事件优先度按,紧急程度和重要程度进行划分。就出现了我们常用的四种情况的划分
对于重要事情的定义:影响群体利益的事情、上级关注的事情、影响绩效考核的事情、价值重大的事情
电商运营的时间管理策略
重要不紧急(制定工作计划):产品优化上新、数据分析、广告投放推广、工作流程优化
重要紧急(马上执行):客户投诉、差评、将到期的任务、新政策理解
不紧急不重要(对它说不):同事的打断、不合理的请求
紧急不重要(抽空/交由下属解决):临时客户咨询、物流进度跟进、款项发票跟进、付款申请
缓急轻重、有条不紊就是日常需要修炼的重要课程,矩阵思维背后是对信息纬度关联性的思考后主观 判断作出决策并进行精力再分配。
机会成本:为了得到某种东西而必须放弃的东西。
一个人不可能同时把所有的事情做到最好。再好的时间精力资源管理,追求的是总效用最大化,而不是每个单项的完美。在电商运营时也一样,不可能同时把精力投入到供应链、运营、推广、跨平台全面铺开,只能说阶段性的找重点作突破,才能效用最大化。
效率就是节约用户注意力。
持续补充~
URLLIB 是Python 的内置HTTP请求库包含四个模块:
URL
URL(Universal Resource Locator) 统一资源定位符
URI(Uniform Resource Identifier) 统一资源标志符
通过URL/URI来唯一指定了它的访问方式。
Hypertext
在浏览器看到的页面是超文本解析而成
HTTPS
HTTP(Hyper Text Transfer Protocol)超文本传输协议
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer)
以安全为目标的HTTP通道
REQUEST
Requst 请求分四部分内容,Request Method、Request URL、Request Headers、Request Body
Request Method : GET 和 POST
包含敏感信息使用POST方式请求
GET提交数据限制1024字节,POST没限制
Request Headers :用于说明服务器使用的附加信息 ,Cookie\Referer\User-Agent
Request Body :承载POST一个请求中的FORM DATA ,对于GET请求Request Body 为空
Content-Type|提交数据方式
—|—
aapplication/x-www-form-urlencoded |Form 表单方式
multipart/form-data\ |表单文件上传提交
application/json |序列化Json数据提交
text/xml |XML数据提交
本文价值:闲谈